1. 반복문
- while: 조건 충족 시 반복(True인 한 반복)
- for: iterable의 반복(횟수)
if문과 조합되는 명령어
- continue는 마주치는 순간 반복문으로 돌아감(복귀)
- break는 루프를 탈출함
2. Range loop function
- range(시작, 끝, 스텝)
- range(시작, 끝, -1): 역행 (= [last:first:-1]; List)
3. 선언
- string = ''
- list = []
- dic = {key: value} (dict는 sequence 변수가 아니다.)
- list는 나열, 딕셔너리는 키워드 값의 나열
- list는 인덱싱, 딕셔너리는 키값으로 데이터에 접근
- dict[key] >>> value
- list[index] >>> value (like enumerate). index가 key인 것
4. String
- 문자열은 immutable(정수, 소수, 문자열, 튜플). 때문에 변수에 str의 재명명과 합연산은, 기존의 str을 초기화하고 새로운 객체를 반환하는것
- str.replace('타겟-바꿀 문자', '변경 후 문자', 횟수-부재 시 모든 타겟문자 변경): str 중 문자 교체는 replace
string = 'hello'
string = 'hell' # 기존 hello는 삭제됨
string += 'world' # 마찬가지로 기존 hello는 사라지고 hello world가 할당- str.split(타겟 문자): str을 타겟 문자를 기준으로 잘라서 list 생성(결과 = list, 원소 = str)
- a, b, c = input().split(','): list의 언패킹
- str의 각 원소를 분리해 list로 넣으려면 list(str)

- str[n] str[-n] str[n:] str[:n] str[::n]
- st[::-1] 문자열 뒤집기
- str.index('A'): A의 위치
- str.index('A', n, m): n~m번 문자 사이에 A의 위치
#1 str slicing과 연산
sam = "life is too short"
sam[3] # 3번 위치에 있는 문자
sam.index('t') # 'l'이 있는 위치
sam.index('t', 9, len(sam)+1) #0~16까지 17개
sam[8]+sam[9]+sam[10] #'too'
print(sam[8]+sam[9]+sam[10]) # too
sam[8:11] # too. slicing ## 8이상, 11미만임을 기억할 것
sam[8:] # 끝까지..!
sam[::2] # 2 칸씩 이동
#2 문장 뒤집기
string = '이번역은 역삼역입니다.'
sen = '' # 새로 string을 만든 느낌
i = -1
for a in string:
sen += string[i]
i -= 1
#2.1
string[::-1]
5. List
- a[0]은 특정 위치의 원소만 인덱싱으로 가져온다([2,1]도 원소이다. 단일 정수 원소와 같은 size)
- a과 a의 slicing은 list 전체를 가져온다
- a[n] = m 으로 그 위치의 원소만 수정할 수 있다
- a[1:3] = [1,2]로 splicing 수정도 가능. 지정 범위보다 추가하려는 수가 적으면 일부 사라짐. 많으면 추가됨
- string은 같은 방법으로 수정 불가
- list(data)는 새로운 리스트를 만들고 여기에 data를 추가함. 새 객체이므로 주소가 다름

명령어
- 추가
- list.append(value)와 '+', list.extend(list2): List 마지막에 value 삽입
- list.insert(index, value): index에 value 삽입
- 제거
- .remove(value): 첫번째 value에 접근
- .pop(index): index로 접근. 기본 설정은 맨 뒤 value 제거
- del list[index]: index로 접근(dict도 key로 접근)
- list.clear(): list 비우기
- 정렬
- list.sort(): list 정렬 적용
- sorted(list): 정렬된 list를 보여줌(적용 X)
- list.reverse(): 뒤집기
- reversed(list): 뒤집어진 list를 보여줌
- index
- list.index(value): value의 위치
5-1. List loc
| 이름 | 기호 | 설명 |
| 대괄호 | [ ] | 레이블과 위치정수로 인덱싱 |
| 레이블 인덱싱 | .loc[label] | 레이블 기반 인덱싱 |
| 위치 인덱싱 | .iloc[position] | 위치 정수 기반 인덱싱 |
| 슬라이싱 | [ : ] | 슬라이싱으로 인덱싱 |
| 레이블 인덱싱 | .at[label] | 레이블 기반 인덱싱. |
| 위치 인덱싱 | .iat[position] | 위치 정수 기반 인덱싱 |
- df.loc[ : , : ] >> 문자(특화), 조건
- df.iloc[ : , : ] >> 숫자, slicing
| a row | rows | a column | columns | a row & a column | rows & columns |
| df.loc['a'] | df.loc[ ['a', 'b'] ] | ||||
| df.loc[0] | df.loc[ 0 : 2 ] | ||||
| df.iloc[0] | df.iloc[ 0 : 2 ] | ||||
| df.loc[:, 'a'] | |||||
| df.iloc[:, 1] | |||||
| df['A'] | df[['A', 'B']] | ||||
| df.loc['1', 'a'] | |||||
| df.at['1', 'a'] | |||||
| df.loc[['1', '2'], ['a', 'b']] | |||||

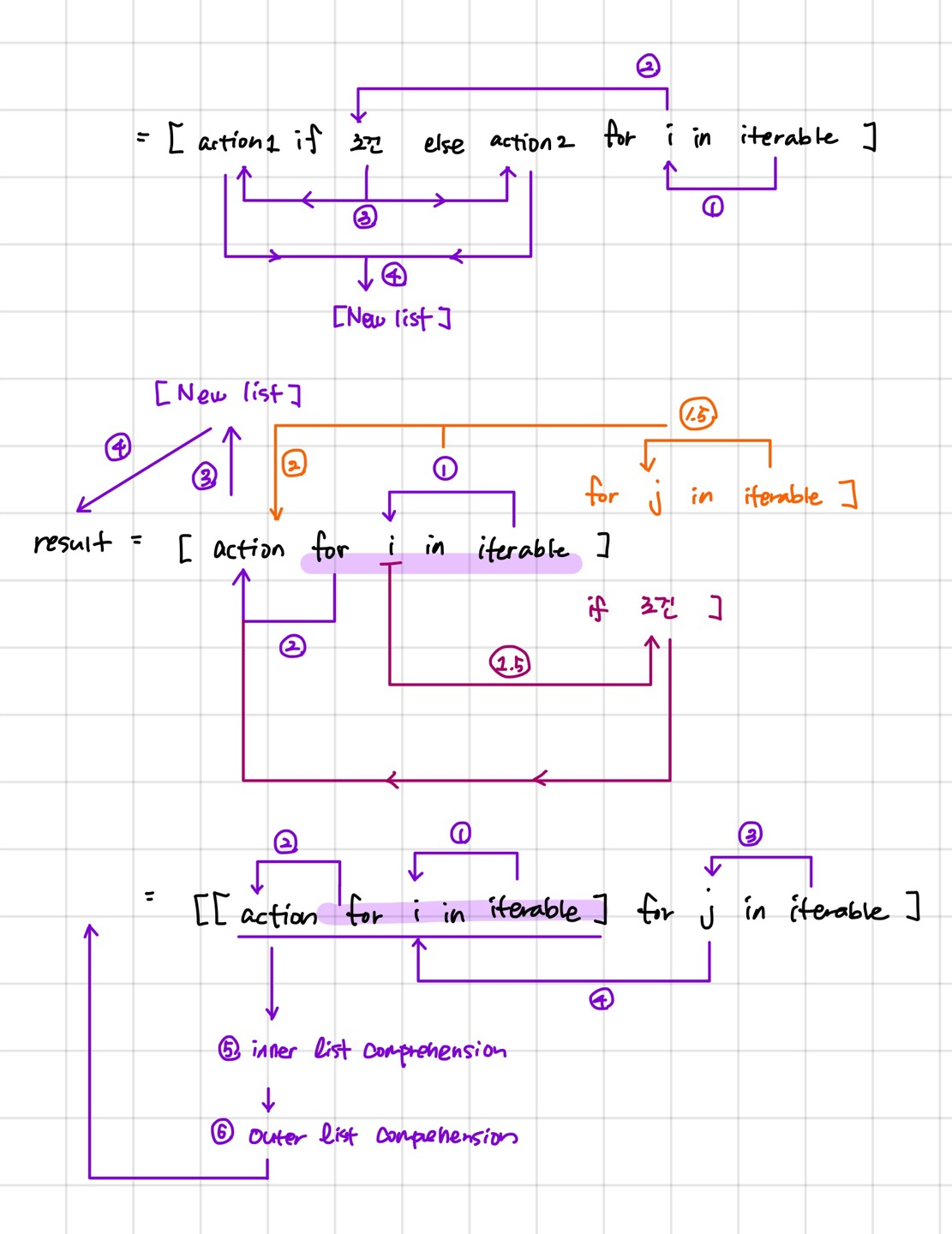
5-2. List comprehension
# 기본 구조 : 표현식 + for문
result = [표현식 for 변수 in 리스트]
# 표현식 + for문 + 조건문
result = [표현식 for 변수 in 리스트 조건문]
# 조건문 + for문
result = [조건문 for 변수 in 리스트]
# 중첩 for문
result = [조건문 for 변수1 in 리스트1 for 변수2 in 리스트2 ...]
# 중첩 List Comprehension
comprehension 과정에서 iterable을 적용한 action 결과들에 대해서 새로운 list가 생성되며, 이후 result에 할당된다(ex) [1st action, 2nd action, 3rd action, ...]
- 표현식 + 조건문 + for문의 경우 조건문 전체가 action으로 취급
- if의 action과 else의 action이 output list에 차곡차곡 원소로 담긴다
- for 중첩문 같은 경우 선 for문부터 순서대로
- for문 + 조건문 같은 경우는 for문 후 if문(조건에 맞는 iterable의 원소만 selecting)
- 중첩 list comprehension은 내부 comprehension을 치환해보면 이해가 빠르다
- inner comprehension을 만들고 outer comprehension을 iterable에 맞게 다시 생성
# 중첩 list comprehension으로 2차원 배열 만들기
result = [ [ 0 for i in range(2) ] for j in range(3) ] # [ [0, 0], [0, 0], [0, 0] ]
# [ 0 for i in range(2) ]를 A로 치환하면
# A = [0, 0]
# [A for j in range(3)]
set, dict, tuple comprehension
### set
set_boy = {n ** 2 for n in range(10)}
print(set_boy)
>>> {0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
## 번외
print(set(range(10)))
>>> {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
# 간단한 range는 이 정도로도 충분(comprehension은 연산에 사용하자)
### dict
from string import ascii_lowercase as LOWERS
dict_boy = {c: n+4 for c, n in zip(LOWERS, range(1, 27))}
print(dict_boy)
>>> {'a': 5, 'b': 6, 'c': 7, ..., 'x': 28, 'y': 29, 'z': 30}
# 연산이 있는 comprehension
## 번외
print(dict(zip(LOWERS, range(1, len(LOWERS)+1))))
>>> {'a': 1, 'b': 2, 'c': 3, ..., 'x': 24, 'y': 25, 'z': 26}
# 간단한 할당
### tuple
tuple_boy = (n for n in range(1, 10))
print(tuple_boy)
>>> <generator object <genexpr> at 0x7f1ac8177db0> # tuple은 unchangable하므로
tuple_boy = tuple(n for n in range(1, 10))
print(tuple_boy)
>>> (1, 2, 3, 4, 5, 6, 7, 8, 9) # 이렇게!
6. Dict
- Dict = {'key': [value, value], 'key': [value, value]}
- key는 list로 다수의 value를 갖을 수 있다.
- dict['key']: value 출력됨
- dict.keys(): key들을 list와 유사한 형식으로 보여줌
- list( dict.keys() ): value in list 형식으로 남겨줌(index로 접근 가능)
- dict['new key'] = new value: 새로운 key와 value 추가
- dict['기존 key'] = new value: 기존 key의 value값 변경
- dict['기존 key'] += value: key 값에 value를 합연산
- dict.values(): value만 list로
- dict.values()의 결과도 list처럼 쓸 수 있는 객체라 바로 sum을 받을 수 있음 ex) sum(d.values)
- dict.items(): [( , ), ( , )] tuple 형태로
- 제거
- dict.pop(key): key를 같는 key-value를 출력하면서 제거. dict는 순서가 없어서 그냥 pop만하면 에러가 남(list는 뒤부터 pop)
- pict.popitem(): 맨 뒤 item만 탈출
- del(dict[key]) ;; pop은 값을 지우면서 값을 반환, dict는 지우기만 함. 용도가 다르다.
- dict.get(key): value만 가져오기. menu[' a ']와 다르게 조회 시 key가 없으면 none이 나와서 error가 없음
- print(i) for i in dict: key값 조회. items tuple의 첫째 elements = dict.keys()를 iter

7. Tuple
- 튜플은 편집 불가. immutable. 불변값으로 조회만 가능함
- 요소 1개의 튜플은 (3,)이나 3,로 표기함( (3)은 int이다)
- a = 1, 2, 3도 a = (1, 2, 3)도 tuple이다.
- 튜플도 인덱스로 접근 가능함
8. sequence 자료형
- list, tuple, range, 문자열: index로 접근 가능(연속적, 순서)
- element: sequence 객체에 들어간 값
- dict와 set은 sequence 변수가 아니므로 순서가 없다.
- set은 중복도 없으므로 list(set(list))) 형식을 이용해 중복값을 지울 수 있음
- 문자열 간에 '+'는 연산이 아니라 연결 연산자이다(곱하기도 가능) .
- 튜플을 연결할 경우, 새로운 튜플이 생성됨
- range는 별개로 range 타입 iterable
9. In
in은 변수가 iterable내에 있는지 여부를 물어볼 수 있는 편리한 명령어
fruits = ['사과', '포도', '홍시']
fruit = input('좋아하는 과일은?')
if fruit in fruits:
print('정답')
else:
print('오답!')- for in(반복) != if in(1회성, bool): 각기 다른 action
- 'a' (not) in seq: bool 형태로 존재 유무를 반환
10. Function
- 함수: 특정 동작을 수행하는 일정한 코드의 모임
- print, int, string, input, print, del, type, range 등: 내장함수
- 매개변수를 투입하면, 수행명령(함수이름)을 실행하고, 반환값을 토해냄.
따라서, 함수는 매개변수를 받아서 반환값을 만들어주는 상자를 만드는 것 - 장점: 1. 가독성 2. 재사용성(함수-모듈화/클래스-캡슐화)
- But, 성능에는 큰 영향이 없음
# 함수정의
def 함수이름(매개변수):
수행명령
return 반환값
def hi():
print('hi') ## hi를 출력하는 사용자 정의 함수
hi() ##호출 필요- hi를 입력하면 함수가 저장된 시작점을 출력
- print(hi)는 저장소 내 위치를 알려준다
- 함수는 '매개변수'를 받기 때문임
- 반환값을 받고 싶다면 return이, 동작을 실행하고 싶다면 명령어(print 등)을 넣어주어야 함
- 함수는 return을 만나면 언제든 종료
def nick(nick):
if nick in [비속어]:
return ## 종료
print('나의 별명은 nick')- def 함수(*args) : 매개변수가 몇개든, 가변적인 인자 수를 모두 받을 수 있음. *는 가변인자 처리 약속. *args는 튜플로 받는다.
- 반면, def 함수(*args, 인자): error
- *args는 무한으로 받아오기 때문에 특정 매개변수가 어느 위치에 있는지 알 수 없음
but, 호출 시 인자='a'로 해주면 정상적으로 돌아감.

10. map 함수
: map(function, iterable)
- builtin 함수. type은 map
- function에 iterable의 item들을 인자 arguments로 전달하여 실행
- function의 parameter 수 만큼 iterable이 전달되어야 함
- iterator: 값을 만드는 규칙을 저장하고, 필요할 때 순서대로 값을 만들어주는 자료구조. 값을 차례대로 꺼낼 수 있는 객체입니다.
- iterable: 반복 가능한 객체입니다. 예를 들어, 리스트, 튜플, 문자열 등이 있습니다.
간단히 말해, iterable은 반복할 수 있는 객체이고, iterator는 그 객체를 반복하는 도구(행위를 도와줌)입니다. map 함수는 주어진 함수와 이터러블(예: 리스트)을 인자로 받아, 이터러블의 각 요소에 함수를 적용한 결과를 반환합니다. 그러나 map 함수 자체는 이터레이터를 반환하기 때문에, 이를 리스트나 다른 이터러블로 변환하지 않으면 함수의 주소를 출력하게 됩니다. 즉, 이터러블 객체가 아닌 이터레이터를 반환하기 때문에, 변환을 위한 이터러블이 필요합니다.
# iterable은 __iter__() 메서드를 가지고 있으며, 이 메서드는 이터레이터를 반환합니다
my_list = [1, 2, 3]
for item in my_list:
print(item)
# iterator는 __next__() 메서드를 가지고 있으며, 이 메서드는 다음 값을 반환합니다.
my_list = [1, 2, 3]
my_iterator = iter(my_list)
print(next(my_iterator)) # 1
print(next(my_iterator)) # 2
print(next(my_iterator)) # 3
Q. list의 모든 값에 1씩 더한다
- A1. 한개 원소씩 접근해야하는 번거로움
#1 dict
dict = {'a': 1, 'b': [3, 4]}
dict['a'] += 4 # 5
dict['b'] += 4 # error. list 원소에 산술연산 불가
#2 list
a = [1, 2, 3]
a[0] += 1 # [2, 2, 3]
a += 1 # 전체 원소에 1 더하기는 불가
#3 iterator 사용
# for(iterable)로 mylist를 받아와서 원소 i로 연산한 값을 새 list에 더한다.
mylist=[1,2,3]
result = []
for i in mylist:
result.append(i + 1)
print(result)- A2. 해결
#1
# 함수를 정의하고 iterable 기능을 탑재한 map이 parameter의 iterable을 돌면서 수행
def add_one(n):
return n+1
result2 = map(add_one, mylist)
print(list(result2)) # map 까지는 주소만 알려줌. list로 감싸주어야 함
#2
# parameter 수 만큼의 iterable이 필요
def inti(a, b):
return int(a+b)
f = (3.14, -5.1, 100.4, 25.8)
c = (3.14, -5.1, 100.4, 25.8)
print(list(map(inti, f, c)))
11. zip, enumerate, filter 함수
1) zip
- zip(*iterable)
- 각 iterable 동일 index의 item들을 튜플 쌍으로 변환. zip type
- iterable 간의 길이가 달라도 무방
list(zip('abc', range(3), range(3,6)))
2) enumerate
- enumerate(iterable[, start=0])
- (idex 번호, value) 튜플쌍 생성, iterable에 숫자를 붙여줌
- start는 시작 번호로 생략 시 0. enumerate type.
3) filter
- filter(함수, iterable)
- function에 true인 iterable 내 argument만 가져옴
numbers = [ 1, 2, 3, 4, 5] print(list(filter(lambda x: not x%2 , numbers))) # filter 대신 map이 들어가면 bool이 출력
zip;튜플화 ( - 숫자 라벨링 > enumerate)
map;함수 실행 ( - Function True만 필터링 > filter; lambda) # filtler는 filtering해서 반환, map은 변환
12. lambda 함수
- lambda 매개변수: 결과(반환할 값) ex) list(map(lambda x: x+1, iterable list))
- 정의와 동시에 사용. 저장되지 않아 메모리 절약 가능
- function_name = lambda a, b : a+b 식으로 명명도 가능(그러나 굳이) # function_name(2, 3); 사용
- 사용하는 경우 1) 익명함수(함수 이름 불필요) 2) 코드 가독성을 위한 짧은 함수 사용 3) 1회용 함수
- lambda는 filter와도 map과도 잘 맞는다
numbers = [ 1, 2, 3, 4, 5]
print(list(filter(lambda x: not x%2 , numbers))) # filter 대신 map이 들어가면 bool이 출력
13. lambda 함수
sorted는 새로운 list를 만들어주는 함수이다.
- list.sort(): 정렬만 해주는 함수
- a = sorted(list): 재선언이 필수. 때문에 sort()와 다르게 list 외에도 dict, tuple, str에도 사용 가능
# sorted(dict): dict에서 정렬된 key 값의 list만 추출
sorted(dict.items(), key = lambda item : item[1])- dict. items 실행
- item의 value 값을 key로 정렬
- 출력 ((key1, value1), (key2, value2))
points =[(1,2), (3,4), (5,1)]
sorting = list(sorted(points, key=lambda x: x[1]))
# sorted(iterable, key= ) > list인 sorting 생성
# 원소에서 key가 되는 point는 무엇인가?
# points의 원소인 각 (a, b)이 x이다. key는 전체 list가 아니라 가장 큰 원소를 받아 옴
print(sorting)
# 그 외에 글자 수 순서대로 정렬하려면? ex) sorted(list, key = leng)
14. module
- module: 파이썬 코드로 이루어진 파일. 함수, 변수, 클래스 등 다양한 코드가 들어있음
ex) import 모듈명(.변수, 함수, 클래스-특정 ) as 별명 ; 모든 모듈, - from 모듈명 import 함수명/클래스명 ; 모듈 내 일부 함수나 클래스
- 모듈이 또 합쳐진 것 = package. 관련된 모듈의 집합, 모듈을 담는 디렉토리
mport math as map
m. pow(2, 4)
from math import pow
pow(2,5)
15. class
- class : 똑같은 것을 만드는 틀, 설계도
- object: 클래스에서 찍어낸 형태
class 이름:
def __init__(self, 초기화값): # class 호출 시마다 자동으로 불러옴
멤버 초기화
method 정의
참고문헌
[파이썬] iterable과 iterator 의 차이가 뭐예요?
[Python] list comprehension에 대한 즐거운 이해 - Parkito's on the way
'공부 > 컴퓨터 언어' 카테고리의 다른 글
| Python 시각화: matplotlib과 seaborn (1) | 2025.02.03 |
|---|---|
| [cmd/Linux] Linux 명령어 정리 (1) | 2025.01.10 |
| python 기초 (4): activity (0) | 2025.01.07 |
| 파이썬 기초(3): numpy, pandas 외 (1) | 2024.12.29 |
| 파이썬 기초 (1): 기본, print() (0) | 2024.12.28 |


