temp/실습
데이터 분석 실전 연습: Dataframe 활용(달탐사)
시송
2024. 12. 30. 20:51
컬럼명 변경
컬럼 리스트를 '모두 순서대로' 입력(길이가 동일해야 함)
- df.columns = ['a', 'b', 'c']
특정 위치 컬럼의 이름 변경
- df.columns.values[n] = 'a'
needed_samples_overview.rename(columns={'ID' : 'Number of samples'}, inplace=True)- df.rename(columns={변경 전 컬럼명:변경 후 컬럼명 }, inplace = True)
- df.rename({변경 전 컬럼명:변경 후 컬럼명 }, axis ='columns')
- df.rename({변경 전 컬럼명:변경 후 컬럼명 }, axis = 1)
- 함수를 이용해, dict 타입으로 지정하여 변경(기존이름key를 새로운이름 value로 변경)
ex) df = df.rename(columns = lambda x: '[' + x +']')
- 함수를 이용해, dict 타입으로 지정하여 변경(기존이름key를 새로운이름 value로 변경)
데이터 탐색
- .value_counts(): NaN값은 무시된 모든 데이터 수 카운팅
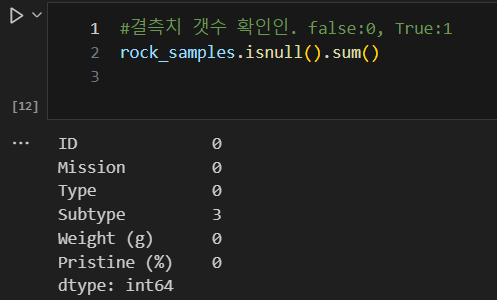
- isnull().sum(): isnull()로 컬럼별 TF DF 생성 후, 컬럼별 T 갯수 sum()
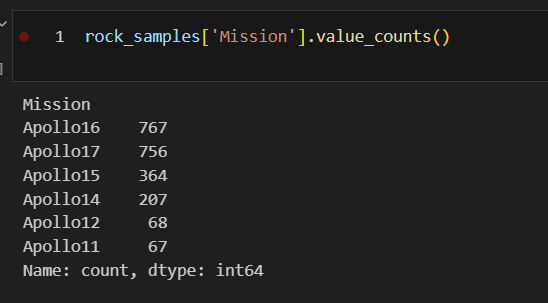
sample_total_weight = df.groupby('Mission')['Weight (kg)'].sum()- 'Mission'.unique()로 group
- 'Mission'.unique() 별 'Weight (kg)'으로 sum()
# rock_samples 데이터프레임에서 암석유형별('Type') 개수를 구해서 total_rock_count 라는 데이터프레임을 만든다.
total_rock_count = rock_samples.groupby('Type')['ID'].count().reset_index()팬시인덱싱 응용
#1
(df['Weight (kg)'] >= 0.16) & (df['Pristine (%)'] <= 50)
#2
low_samples = df[(df['Weight (kg)'] >= 0.16) & (df['Pristine (%)'] <= 50)]
low_samples = df.loc[(df['Weight (kg)'] >= 0.16) & (df['Pristine (%)'] <= 50)]
low_samples[low_samples['Type'].isin(['Basalt', 'Breccia'])]
df[df['Type'] == 'Crustal'].head(5)#1 TF series
#2 팬시 인덱싱 in DF
- 논리 연산자 이용
- .isin() 이용
- Type이 Crustal인 data만 추출
데이터 간 연산/데이터 간 조정
- df[컬럼명].diff(): 현 행과 앞 행간의 차를 표시한다
- df[컬럼명]-df[컬럼명].shift()
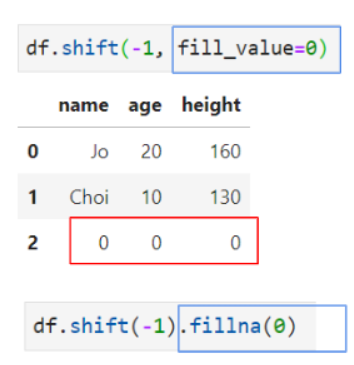
- df.shift(n)을 사용했을 때, n의 수만큼 행이 아래로 내려간다.
- 음수 넣으면 , 반대로 행이 위로 올라가게 된다.
- fill_value 파라미터를 설정해주거나 fillna()함수를 함께 사용하면 결측값 변환이 가능하다
missions['Command Module (CM)'], missions['CM Mass (kg)'] = 명령모듈이름, 명령모듈중량
missions['CM mass diff'] = missions['CM Mass (kg)'].diff().fillna(0)

df.apply(함수)
# 1단계 -> 컬럼값변환 : rock_samples['Weight (g)'] -> rock_samples['Weight (kg)]
rock_samples['Weight (g)'] = rock_samples['Weight (g)'].apply(lambda x: x * 0.001)
#2단계 -> 컬럼명 변환 : 'Weight(g)' -> 'Weight(kg)
rock_samples.rename(columns={'Weight (g)':'Weight (kg)'}, inplace=True)
- 컬럼, 데이터 프레임 전체에 적용 가능한 함수
- 함수 부분에 컬럼이나 데이터 프레임에 적용할 함수 입력(lambda 가능)
테이블 병합
# concat은 row 기준 용이(병합 기준 컬럼 불필요. 기본이 열로 추가)
needed_samples = pd.concat([needed_samples, Crustal])
# merge는 컬럼기준 용이(병합 기준 컬럼 필요)
missions = pd.merge(missions, sample_total_weight, on='Mission')- pd.merge(기존df, 새로운 프레임이나 시리즈, on = 인덱스로 사용할 컬럼명)
기타 함수
- df.drop([컬럼s], axis=1, inplace=True)
- .tolist(): zip과 비슷하게 같은 위치의 데이터끼리 묶어준다. 차이는 list로 묶인다는 점
참고문헌