생성 AI 이론 및 실습
1. 생성 AI의 응용분야
텍스트 기반 이미지 생성, 코드 생성, 언어번역 , 대화형 에이전트,
이미지 기반 이미지 생성, 이미지 채우기, 예술작품 생성, 비디오 생성, 음성합성, 데이터 증강, 의학 이미지 합성
이러한 응용의 기반이 되는 것은
1) Text Generation
- ChatGPT와 같은 GPT(Generative Pre-trained Transformer)에서는 Transformer architecture를 사용
- 방대한 텍스트 데이터를 기반으로 문법, 문맥, 의미론 등을 미리 학습한 뒤, 프롬프트를 제시하면 학습한 패턴을 기반으로 다음 단어나 구문을 예측
- 실사용: 챗봇, 코드 생성, 고객 응대, 카피라이팅 문구 생성
2) Image Generation
- 대표적 생성 기술인 GAN(Generative Adversarial Networks; 적대적 생성 신경망)은 이미지를 만드는 생성자와 진위여부를 판단하는 구별자로 구성된다.
- 생성자는 구별자가 진위여부를 판별할 수 없을 때까지 경쟁적 피드백 루프 학습을 하며 이미지를 개선한다.
- GAN 외에도 VAE, Diffusion 등의 기술이 있고, 최근 발표된 모델들은 주로 Diffusion 모델을 사용(stable 'diffusion')
- 실사용: 예술 디자인, 신약개발, 미술작품 생성, 제품 모형 생성
3) Video Generation
- Video diffusion model 등을 이용하여 비디오 생성. 텍스트 설명을 통해서 장면 생성, 특정 비디오에서 누락 또는 손상된 프레임을 예측하여 보충
- 비디오 생성은 시간 요소가 포함되기 때문에 이미지 생성보다 더 복잡
4) Audio Generation
- 음성/소리 분야에 GAN 기술이 적용됨 (WaveGAN)
- 대량의 데이터셋을 학습하여 소리 뉘앙스를 습득, Tacotron 2와 같은 TTS(Text-To-Speech, 텍스트를 음성으로변환)는 텍스트를 입력 받아 음성 생성
- 실사용 : 광고/비디오 등 배경음악, 효과음 생성, 광고 나레이터
2. 이미지 학습
1) GAN
- discriminator: generator보다 더 많이 학습되어 생성된 이미지를 판별함. 생성된 이미지가 분포를 따르도록 가이딩
- generator: 노이즈 기반으로 원본과 가까운 가짜 이미지를 생성, 학습을 하여 원본 데이터 분포를 따르게 됨
2) AutoEncoder
- 인코더에 데이터 투입하면 compressed data로 구성된 잠재공간(바틀넥) 생성
- 바틀넥의 적합성 다시말해 압축 정도가 적합한지를 판단
- 판단방법:
잠재공간에서 reconstructe된 output이 encoder와 같은 성격을 띄는가? - 존재이유:
학습 축적에 따라 이미지 변수(분류지표)가 점진적으로 증가하므로, 학습 데이터에 과대적합이 발생하지 않도록 차원을 축소/압축하는 과정이 필요 - 예를 들어, 다차원 데이터의 2차원화(2가지 변수에 집중해 차원 축소)
3) VAE (Varitional AutoEncoder)
- 오토인코더의 변이 (분포를 이야기하는 알고리즘)
- 인코딩 된 학습 데이터의 통계값과 비슷한 분포를 갖는 이미지를 생성함
4) 확산모델
- 학습데이터에 잡음을 추가해 손상시킨 후 잡음을 제거하며 원상복구해나가는 생성모델(denosing)
- 순방향 확산:
가우시안 분포에 따르면 기존 이미지 데이터의 각 픽셀은 시간이 지남에 따라 일정한 규칙으로 확산(퍼짐)되어 노이즈를 형성한다. 노이즈는 아무런 특징이 없는 잡음이다. - 역방향 확산:
확산 규칙을 학습하여 이를 역행시키면 원래대로 복구도 가능할 것이다 - 다시말해, 잠재공간인 바틀넥에 들어가며 축소되는-노이즈가 끼는-과정을 관찰하는 학습모델은 이를 역으로 돌려 복구도 가능할 것이다.
3. Stable Diffusion 이론
1) Stable Diffusion의 기본구조
Stable Diffusion = CLIP + UNET + VAE

- CLIP: 입력된 텍스트를 인코딩하여 Token 형태로 변환(토큰화) 후 UNet에 전달 (텍스트를 받아들이고 임베딩을 받아 조건 전달)
- UNET: 전달된 Token으로 무작위 생성된 잡음(noise)을 denoising (반복하여 제대로 된 이미지를 생성하는 핵심부분)
- VAE: 이미지를 픽셀로 변환

큰 해상도의 이미지를 생성하는데도 리소스 사용량을 대폭 줄여 PC 그래픽카드 정도로도 이용 가능
- 기존 모델
: 이미지 크기가 커질수록 리소스 사용이 기하급수 적으로 증가함 - Stable Diffusion
: 오토인코더를 적용하여 이미지 전체가 아닌, 작은 차원의 잠재공간(latent space)에서 노이즈를 삽입 및 제거
2) Base model of Stable diffusion
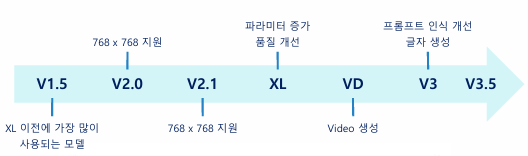
: 체크포인트 별로 최적화된 사이즈가 다르다(ckpt는 512 512, sdxl은 1024 1024)
3) Fine tuned model
노드 간을 잇는 가중치(filter, kenel)들을 재학습 시킨 모델. more specification on a setting point
- Lora는 fine tuned보다 low rank에 영향(전체에 영향을 주는 fine tuned model보다 크기도 작음)

4) Web UI
모델을 올려 활용할 수 있는 UI 중 가장 대중적 UI. webUI forge는 webUI의 강화판
4. Stable Diffusion 실습
4.1 webui-forge 명령어
webui-forge 실행
1. ssh -i C:\Users\USER\Downloads\키이름 azureuser@아이피 -p 50000 (경로 붙이고\파일이름)
2. 가상환경 활성화: conda activate webui-forge
3. 폴더이동: cd stable-diffusion-webui-forge
4. 런쳐실행: ./webui.sh --theme dark --enable-insecure-extension-access --share --gradio-auth 아이디:비번
civitdl 모델 설치
1. cd ~/Stable-diffusion-webui-forge/models/stable-diffusion 폴더 이동
2. civitdl 사이트 air번호 . -k7. api 키
hugging space 모델 설치1. cd ~/Stable-diffusion-webui-forge/models/stable-diffusion 폴더 이동
2. wget https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_canny.pth (허깅페이스 카피 주소)
+) url 설치 오류: 확장기능 옵션 추가
./webui.sh --share --enable-insecure-extension-access
1) Lora
Webui에서 lora 웹 환경 업데이트

2) wrong lora
- negative promopt에 들어갈 프롬프트를 모두 학습(부정프롬프트를 학습시킨 Lora)
- wrong lora는 부정 프롬프트에 wrong을 가져와야 함
minimaxir/sdxl-wrong-lora · Discussions
minimaxir/sdxl-wrong-lora · Discussions
Does this work for ControlNet SDXL as well?
huggingface.co

4.2 txt 프롬프트 예시


1. A sorceress
2. Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing
3. Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting
4. Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body
5. Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha
6. Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation
7. Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly beautiful, dystopian, iridescent gold
[prom]
A young woman ,full body, showing hands and shoes, standing pose, wearing shirts and jeans, forest background, extremely beautiful and delicate (light makeup), with brown hair, sweet smile, delicate and beautiful fair skin, realistic and exquisite facial features, high nose bridge, red lips, beautiful and gentle girl, flowing and smooth hair, extremely delicate hair, soft temperament, facial lighting, surreal, realistic, 8K image quality, extreme details, realistic details, master works, Realistic to the extreme, body shape, stunning, pure desire, stunning beauty, unparalleled beauty, highest picture quality, 8k resolution, goddess, smile, fine facial features, brown hair, long legs
[neg]
(nsfw:1.5),(worst quality, low quality:1.4), signature,no anime girl, human,no anime character, sketch, duplicate, ugly, huge eyes, text, logo, monochrome, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), ((2girl)), (deformed fingers:1.2), (long fingers:1.2),(bad-artist-anime), bad-artist, bad hand, extra legs
[ Refiner ]
- 프롬프트 : girl alone. photo, solo, incredibly absurd, hoodie, headphones, street, outdoor, rain
- 부정 프롬프트 : disfigured, ugly, bad, immature, carton, anime, painting, b&w
[ 손가락/건반 이미지 ]
- 프롬프트 : Photo, incredibly absurd, 1girl, looking at viewer, playing piano, blue eyes, pale skin, black hair, straight hair, modern room, artistic composition, perfect face, vibrant color, light and shadow
- 부정 프롬프 : anime, painting, disfigured, ugly, immature, carton, painting, low contrast, noisy, (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, ((monochrome)), ((grayscale)) watermark
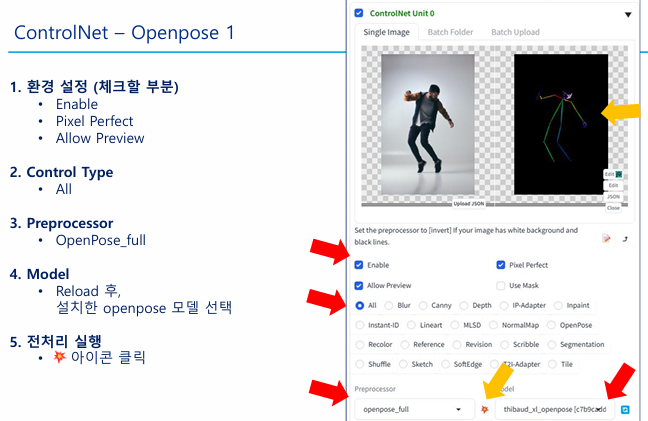
[ ControlNet Openpose : 프롬프트 ]
- 프롬프트 : 1 woman standing at home
- 부정 프롬프 : anime, painting, disfigured, ugly, immature, carton, painting, low contrast, noisy, (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, ((monochrome)), ((grayscale)) watermark
[ ControlNet Openpose 2 : 실습 이미지 만들기 ]
- 프롬프트 : (knee shot:2), (full body:2), beatiful asian woman, a young female, highlights in hair, standing outside restaurant, smile, blue eyes, wearing a dress, side light, masterpiece, HDR, UHD, photorealistic
- 부정 프롬프트 : disfigured, ugly, bad, immature, b&w, nsfw
+) 사용자 지정 프롬프트 프리셋을 만들고 사용할 수 있다.

🔍 부정 프롬프트
portrait photo of a man
portrait photo of a man without mustache
without mustache는 오히려 수염이 풍성해지는 효과. 부정프롬프트에 mustache를 입력해야 함. 샘플링 시 남성 이미지 중에서 수염이 있는 경우 모두 제외하기 때문
Q. 코끼리를 생각하지 마시오
- 인간: 코끼리...코끼리...
- AI: 이미 코끼리를 학습해버렸어:9
4.3 기본 설정
1) batch
- batch count: 총 생성 횟수
- batch size: 한 번에 생성할 이미지 갯수
if) count 3, size 2라면, 2개씩 3번 이미지가 총 6개 생성됨
2) 난수 seed
- -1: 랜덤 포즈로 이미지 생성
- 1: 이전에 생성된 이미지와 유사한 이미지 생성
- 이전 사진 seed 복붙: 그 사진에서 수정
4.4 이미지 수정
- Outpainting
: 현재 이미지와 유사한 느낌으로 이미지를 특정 방향으로 확장 - Upscaling
: 화질 개선 - Inpainting
: 생성된 이미지에서 마음에 안드는 부분이 있을 때, inpainting 기능을 이용하여 다시 그릴 수 있음 - refiner
: 더 실제처럼- switch at: 20% 남았을 때 refiner가 정제작업을 시작하겠음

- denoising stregth
: 잠재공간에 넣고 뺄 때, 노이즈를 넣고 빼는 것을 얼마나(양적) 할지(높을 수록 원본과 달라짐) - ControlNet
: 구도 및 피사체의 자세를 복제할 수 있는 신경망(특정 네트워크를 제어하기 위한 네트워크를 부르는 말. canny, Depth, mlsd 등을 제어하는 네트워크)- conrolnet은 zero convolution으로 윤곽을 형성하여 decoder 과정에 영향을 준다.
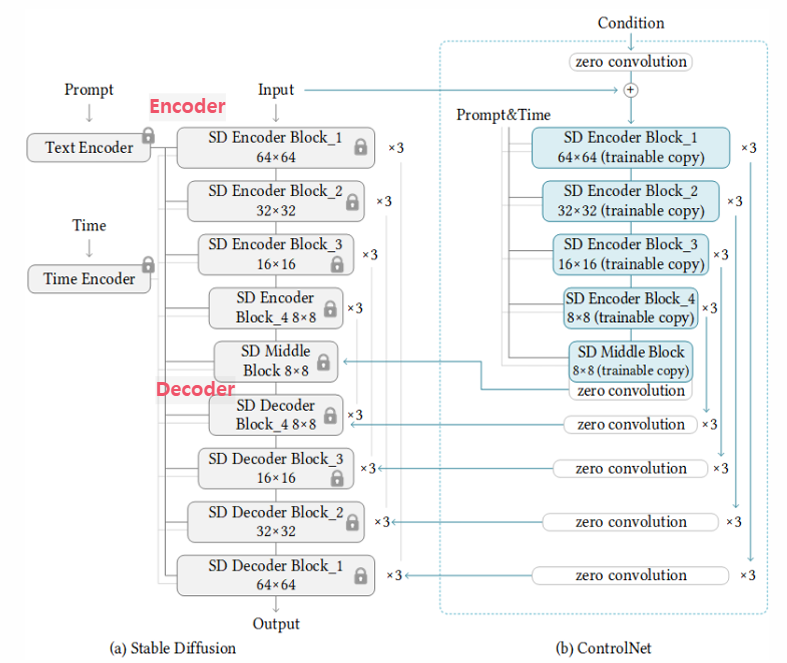
5. ControlNet
1) openpose & editor
2) 그 외 네트워크 확장자
| canny | 스케치한 것처럼 선을 따서, 그 선으로 새로운 이미지를 생성 원본의 화면 비율을 (가로세로픽셀) 유지 |
 |
| Lineart | Canny와 비슷하나 더 섬세하게 라인 추출, 이미지의 외곽선을 감지하여 그림을 생성. |  |
| Scribble | 낙서의 해당구조를 유지하면서 이미지를 생성 |  |
| depth | 이미지의 깊이감을 표현 |  |
| shuffle |  |
|
| Merge | 멀티 ControlNet. 결과를 보고 이미지 별 control weight를 조금씩 수정. - control weight:각 이미지 가중치 |
 |
| MLSD | 건물의 직선형태를 추출하여 프롬프트에 따라 새로운 이미지 생성 | 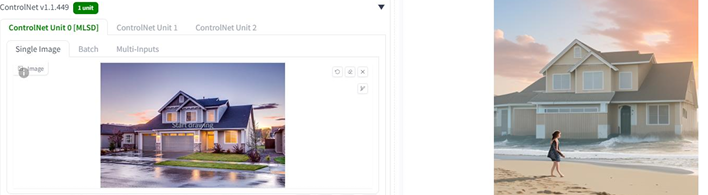 |

3) 추가 확장자
- SDXL Styles: 그림 스타일 지정
- Detail Daemon: refiner와 유사
소소한 궁금증
- webui-forge와 gradio는 무슨 관계인가
- 왜 hugging face는 wget으로 파일을 가져오고, civitai는 civitdl로 가져오는가(자체 기능이 추가돼 있나..?)
- ssh로 가상머신을 켜고, conda로 webui라는 가상환경을 켜주는 것이 맞는가..?